
Echoprint “listens” to audio on a phone or on your computer to figure out what song it is. It does so very fast and with such good accuracy that it can identify very noisy versions of the original or recordings made on a mobile device with a lot of interference from outside sources.
Since anyone can use Echoprint for free or install their own servers, we expect that it will become the de facto music identification technology. And since all the data is available, we expect Echoprint to quickly be able to resolve every song in the world.
Technical details
Echoprint consists of three parts: the code generator, which converts audio into codes, the server, which stores and indexes codes, and the data, which comes from partners and other Echoprint users.
The code generator computes {time, hash} pairs from an audio signal using advanced signal processing to account for noise and modification. Starting from a 11kHz mono signal, we compute a whitening filter, then an 8 band subband decomposition. That decomposition is search for onsets and the onset material is intelligently hashed into a 20 bit space and stored alongside the time of the onset.
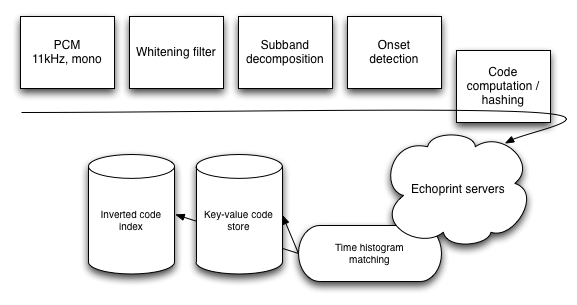
The server code indexes each onset in an inverted index, storing each track’s occurrence of that onset in a long list for fast lookup. We also store the code material for each track as it is needed during matching. Querying is a lookup of all the query codes in the inverted index and the score returned is the number of overlaps of query onsets between the query and each target track. In practice, however, we then filter by the time histogram of the matching onsets to ensure that the onsets occur roughly in “order.” This requires stored data of each onset.
We are currently preparing a whitepaper with more details and of course the source is available.
Accuracy details
We track accuracy of Echoprint through our “bigeval” software that is included with the server installation. Here are some preliminary results:
